


Предмет: Интеллектуальный анализ данных.
Курс: 3.
Университет: РТУ МИРЭА (Московский Институт Радиоэлектроники и Автоматики)
Факультет (институт): КБСП (Комплексной безопасности и специального приборостроения)
Важно понимать, что если вы хотите найти тут объяснения аспектов работы с Deductor Studio, то здесь их не будет. Здесь приведен пример решения конкретной типовой задачи из курса Интеллектуальный анализ данных РТУ МИРЭА.
Пример работы программы
Восстановление пропущенных данных
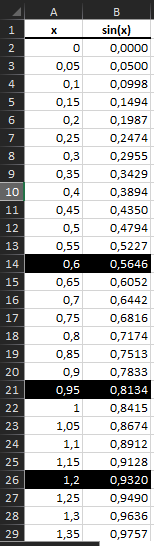
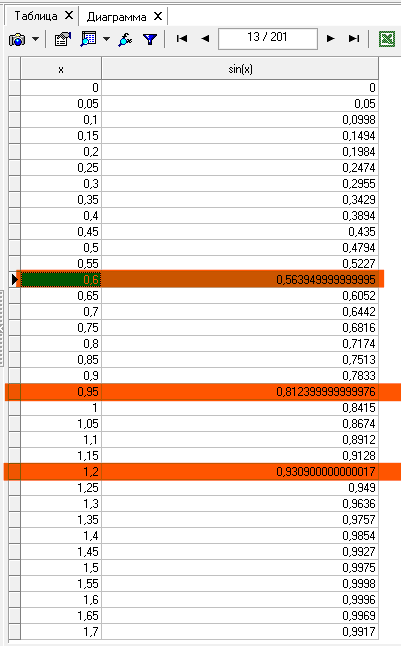
Значения, которые подобрала программа близки к изначальным, что дает нам возможность почти безболезненно для конечного результата восстановить пробелы в исходных данных при четкой функции.
Редактирование аномалий
Ветка

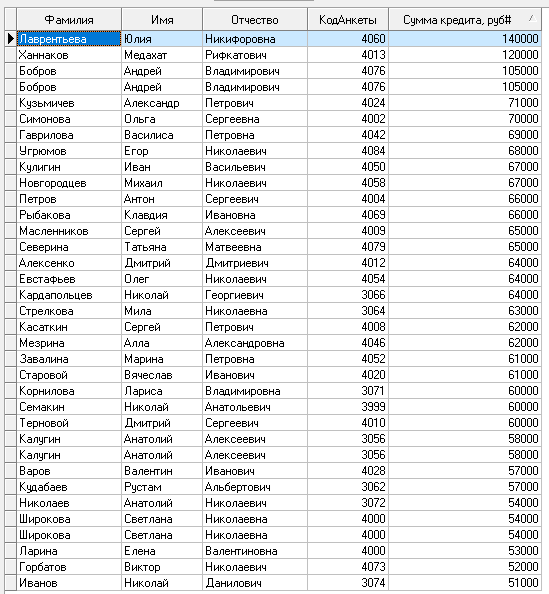
Отсортированная по Сумме Кредита таблица выбросов и экстремальных значений
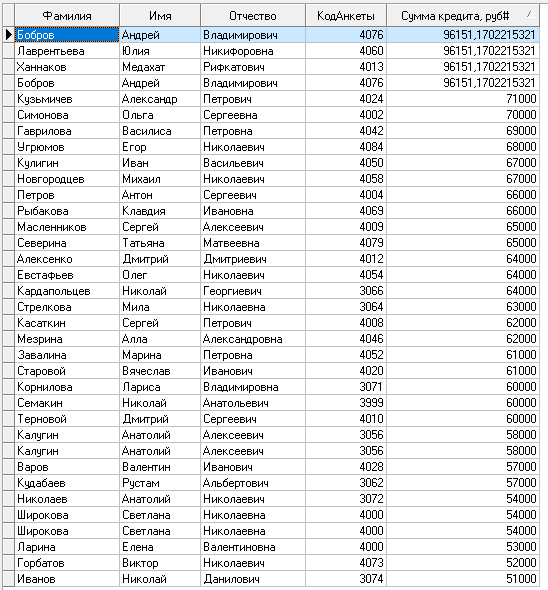
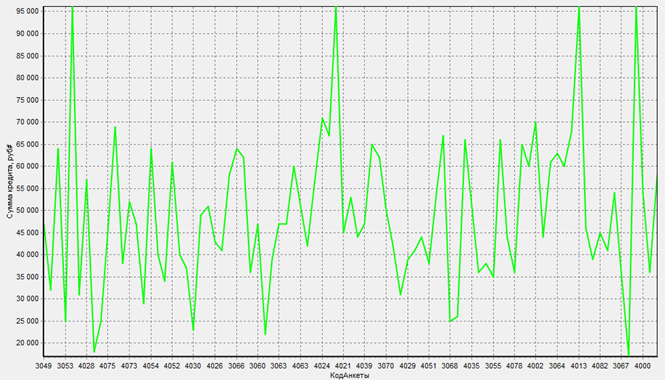
Диаграмма к таблице выше
Оценка качества данных

Исходная таблица значений, отсортированная по Сумме кредита из Анализа качества данных
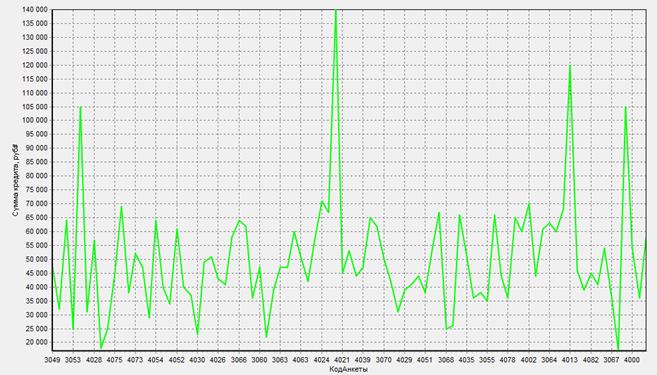
Как мы можем заметить, редактор выбросов сильно снизил пик из первых четырех значений, тем самым уменьшив скачки графика ограничив их в значении ~96151. Исходный график будет виден ниже.
Исходный график из Анализа качества данных без операции редактирования выбросов
Сглаживание и очистка от шумов
Ветка

Исходная таблица значений
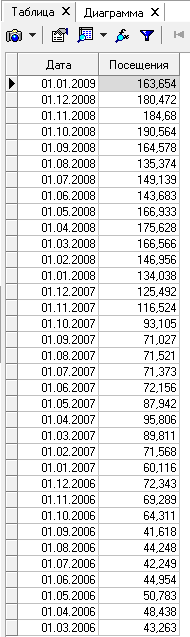
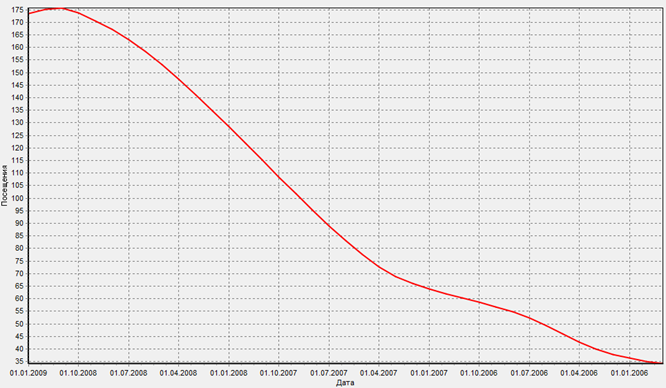
Исходная диаграмма для дальнейшего сравнения
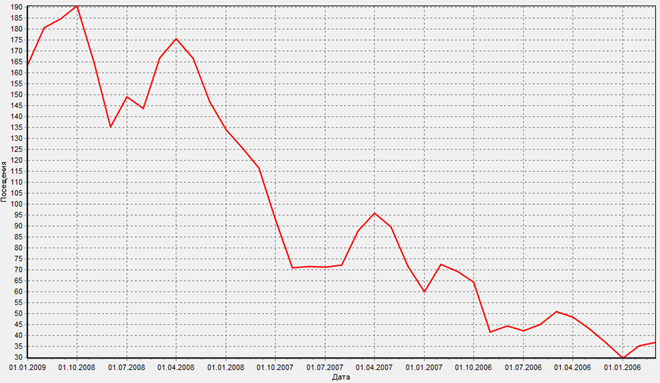
Диаграмма после применения сглаживания
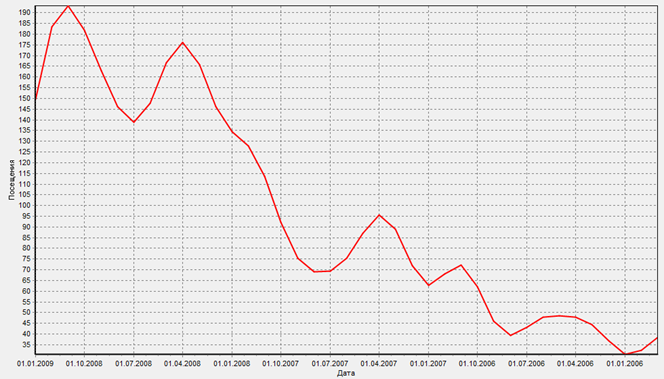
Диаграмма после применения Вычитания шума
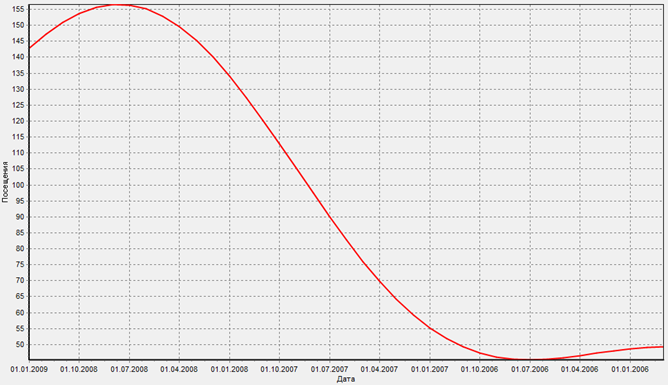
Диаграмма после применения Вейвлет-преобразования
Самостоятельная работа
Проведение парциальной обработки данных, применив к узлу сразу в один прием все три типа обработки: аппроксимацию данных, подавление аномалий большой степени и сглаживание данных с полосой пропуска 50.
Исходный график
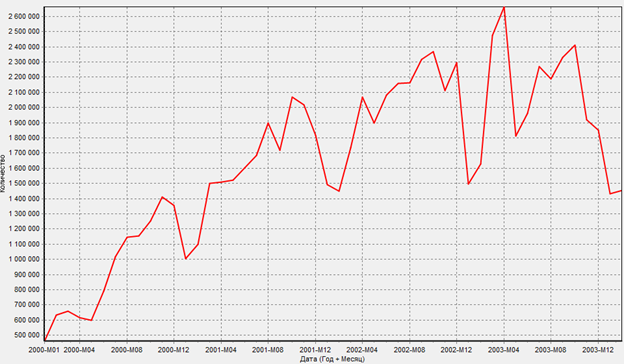
График после проведения парциальной обработки и применения сглаживания
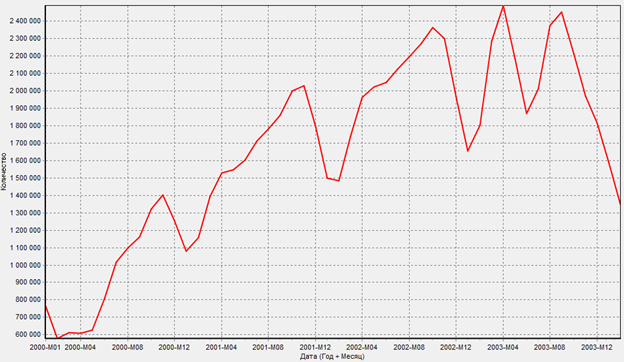
Как мы можем заметить, провалы на графике стали не такими резкими, как это было на исходной диаграмме. Однако, пропали и возможно интересные нам «ступеньки» значений, что дает лишь приблизительное понимание ситуации. Также подобное представление данных значительно сократит время этап подготовки и фильтрации данных для обучения машины.
График после проведения парциальной обработки и применения Вейвлет-преобразования
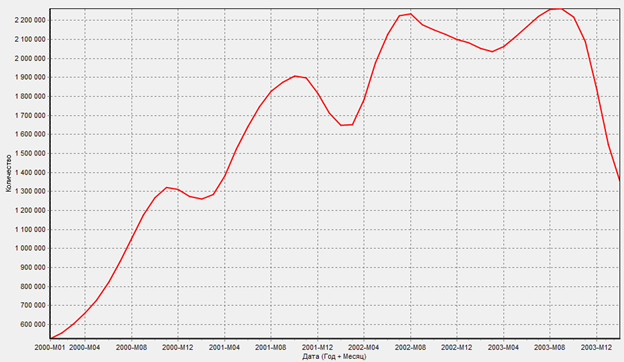
В этом случае анализ несет еще более приблизительный характер, о четком анализе здесь не может быть и речи, однако с подобной визуализацией все еще можно работать, так как это неплохой вариант, чтобы, например, набросать стратегию или понять спрос. Однако, как и в предыдущем примере подобное представление данных так же значительно сократит время этап подготовки и фильтрации данных для обучения машины. Так как шумы и недостоверные данные более не будут мешать обучению.
Ответы на вопросы
- Предварительная обработка данных необходима для очистки данных от мусора на входе, чтобы не получить мусорные данные на выходе.
«Даже самый изощренный анализ не принесет пользы, если за основу взяты сомнительные данные.» - Дубликаты приводят к избыточности, увеличивают объем выборки, при этом не повышая информативность данных.
Противоречия приводят к искажению результата анализа и снижают качество моделей, поскольку нарушают общие закономерности в данных, обнаружение которых и является целью исследования. - Предварительная обработка данных подразумевает под собой комплекс мероприятий с данными. В перечень которых входит и очистка данных. Очистка данных включает в себя следующие этапы:
- Анализ данных
- Определение порядка и правил преобразования данных
- Подтверждение
- Преобразования
- Противоток очищенных данных
- Парциальная обработка включает в себя комплекс инструментов для предварительной обработки данных, таких как:
- Фильтрация
- Оценка качества данных
- Заполнение пропусков
- Редактирование выбросов
- Выявление дубликатов и противоречий
- Спектральная обработка
- Корелляционный анализ
- Факторный анализ
- Пропущенные данные не только могут усложнить процесс анализа, но и испортить данные на выходе, так как различные пропуски могут не отразить на выходе верную картину исследования.
Методы заполнения пропусков:- Оставить без изменения
- Заменять наиболее вероятным
- Заменять случайными значениями
- Заменять средним
- Заменять медианой
- Заменять значением «Не задано»
- Интерполировать
- Удалять записи
- Зашумленные данные, это данные полученные или измеренные с большими допусками или ошибками.
Методы подавления шумов:- Сглаживание
- Преобразование Фурье
- Вейвлет-преобразование
- Вычитание шумов с помощью спектральной обработки
- Сглаживание
- Аномалии при анализе данных создают помехи и сказываются на достоверности информации.
С помощью обработчика «Редактирование выбросов», который предназначен для автоматической корректировки аномальных значений в наборах данных — отклонений от нормального (ожидаемого) поведения чего-либо, мы можем отредактировать аномальные значения.
Для повышения гибкости обработки аномальных значений в узле предусмотрена возможность их разделения, поскольку они в большинстве случаев имеют различное происхождение:
- выбросы – это фактически имевшие место события, вызванные исключительными условиями;
- экстремальные значения – это, как правило, ошибки или фиктивные значения.
Для каждого типа отклонений определяется собственный порог обнаружения, что позволяет сделать процедуру очистки данных более соответствующей логике решаемой задачи (по умолчанию это 3 стандартных отклонения для выброса, 5 стандартных отклонений для экстремального значения).